Blog Details
- Member
- May 12, 2026
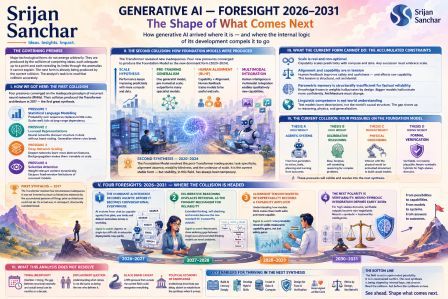
Generative AI Foresight 2026–2031
The Shape of What Comes Next
How generative AI
arrived where it is — and where the internal logic of its development compels
it to go
The governing premise of this analysis: Major technological forms do not emerge
arbitrarily. They are produced by the collision of competing ideas, each
adequate up to a point and each revealing its limits through the anomalies it
cannot explain. The next form is already being produced by the current
collision. The analyst's task is to read that collision accurately.
I
How
we got here: the first collision
The story of
generative AI is not a story of invention. It is a story of inadequacy — the
progressive inadequacy of each dominant approach under the pressure of things
it could not do.
For decades, the
dominant approach to language in computing was symbolic: rules, grammars,
hand-crafted representations of meaning. These systems were precise where they
worked and brittle where they didn't. Every sentence the real world produced that
fell outside the grammar was a failure the system could not recover from. The
anomaly accumulation was relentless.
Statistical methods
arose in direct response to that brittleness. Instead of encoding rules, encode
probabilities — learn the likelihood of one word following another from
observed text. This worked far better at scale but hit its own ceiling: the
statistical approach had no way to represent long-range dependencies. A
sentence that required understanding its own beginning to complete its ending
was beyond what any fixed-window model could handle.
Meanwhile, a parallel
pressure was building from an entirely different direction. Neural networks —
systems loosely modelled on biological neurons — had been demonstrated to learn
representations of data without explicit programming. The key insight, which
took decades to become practically usable, was that representations learned by
networks generalised in ways that hand-coded features never could. The word
"king" minus "man" plus "woman" equalling
"queen" was not a party trick. It was evidence that distributed
representations captured something real about the structure of meaning.
These two streams —
statistical sequence modelling and learned distributed representations — were
pressing against each other and against the dominant paradigms simultaneously.
A fourth pressure arrived to sharpen the conflict: the attention mechanism. The
observation that, when processing a sequence, not all prior elements deserve
equal consideration. Some tokens matter enormously to the current prediction;
most matter very little. A system that could learn which elements to weight
would escape the fixed-window limitation entirely.
Pressure 1
Statistical language
modelling
Probability over
sequences replaces brittle rules. Scales well; fails at long-range dependency.
Pressure 2
Learned
representations
Neural networks
discover structure in data without hand-coding. Generalise where rules break.
Pressure 3
Deep network scaling
Deeper networks learn
more abstract features. Backpropagation makes them trainable at scale.
Pressure 4
Selective attention
Weight relevant context dynamically. Escapes
fixed-window limitations of recurrent models.
When four pressures of
this strength converge simultaneously on a single inadequate paradigm — the
recurrent neural network, which was the dominant architecture of the early
2010s — the outcome is not incremental improvement. It is structural
replacement. The Transformer architecture, introduced in 2017, was not a clever
idea that appeared from nowhere. It was the synthesis that all four pressures
had been demanding. It satisfied all four constraints simultaneously in a way
that nothing before it had.
First synthesis — 2017
The Transformer resolved four simultaneous
inadequacies. It was not invented so much as forced into existence by the
accumulated pressure of things prior architectures could not do. Its arrival
was, in retrospect, structurally overdetermined.
II
The
second collision: how foundation models were produced
The Transformer did
not resolve the field. It reorganised it. Every synthesis creates the
conditions for a new set of inadequacies — and the Transformer was no
exception. It revealed, by being so capable, exactly what was still missing.
The first new pressure
was the scale hypothesis. Researchers at OpenAI and elsewhere observed
something empirically remarkable: transformer performance did not plateau as
compute and data increased. It kept improving, with regularity, in ways that
could be described by power laws. This was not a theoretical prediction — it
was an empirical discovery, and it immediately created a competitive pressure
that no actor in the field could ignore. If capability scales predictably with
resources, then the question of who controls those resources becomes a central
strategic question for the entire field.
The second pressure
came from pre-training. If a model trained on essentially all available human
text would develop generalist capabilities that could then be fine-tuned for
specific tasks, the dominant paradigm of task-specific training was
structurally inferior. A single generalist model, pre-trained at sufficient
scale, would outperform specialist models trained from scratch on most tasks.
This was demonstrated, not argued. GPT-3 made the case empirically in 2020.
The third pressure
arrived from a direction that the technical community initially underweighted:
human feedback. A model capable of producing coherent text was not automatically
producing useful or trustworthy text. Capability and alignment — with human
values, with factual accuracy, with appropriate tone — were not the same thing,
and the gap between them was not closing through scale alone. RLHF,
reinforcement learning from human feedback, offered a mechanism: train a reward
model on human preferences, then use that signal to fine-tune the base model's
outputs. InstructGPT in 2022 demonstrated that a model trained with human
feedback on alignment criteria outperformed much larger models trained without
it. Scale was necessary but not sufficient.
The fourth pressure
was the multimodal argument. Text-only training was a structural limitation
masquerading as a design choice. Human intelligence integrates perception
across modalities — vision, language, spatial reasoning — and a model trained
only on text was working with a fundamentally impoverished signal. The evidence
from vision-language models and image generation systems suggested that
integrating modalities was not merely an extension of the text paradigm but a
qualitative change in what could be represented.
These four pressures —
scale, pre-training generalism, human alignment, and multimodal integration —
converged simultaneously on the base Transformer model and produced the
Foundation Model as the new dominant form. GPT-4, Claude, Gemini, and their
contemporaries are not different inventions. They are different approximations
of the same synthesis, each one absorbing a slightly different weighting of the
same four pressures.
Second synthesis — 2020–2024
The Foundation Model resolved the
post-Transformer inadequacies: task-specificity, alignment absence, modality
blindness, and the underuse of scale. It is the current stable form — but
stability, in this field, has always been temporary.
III
What
the current form cannot do: the accumulated constraints
Every stable
technological form carries within it the anomalies that will eventually force
its replacement. The Foundation Model is no different. Its inadequacies are not
random or contingent — they follow directly from the structural choices that
made it successful.
Before projecting
forward, it is necessary to name what the current form has established as
non-negotiable — constraints that any successor must satisfy, not merely match.
These are the findings that have been demonstrated, not merely theorised, and
which any new synthesis must incorporate or fail.
Scale
is real and non-optional
The empirical
relationship between compute, data, and capability has been demonstrated across
multiple architectures and organisations. No successor model that ignores scale
will compete with one that does not. This is not a hypothesis; it is an
established boundary condition of the field.
Alignment
and capability are in tension
Human feedback
training demonstrably improves usefulness and safety — and demonstrably affects
some raw capabilities. This tension exists. It cannot be wished away. Any new
synthesis must address it structurally, not by pretending one side can be
maximised without cost to the other.
Parametric
memory is structurally insufficient for factual reliability
A model whose
knowledge is frozen in its weights at training time will hallucinate. Not
occasionally, as a bug — structurally, as a consequence of what it is. The
model does not know what it does not know. This is not a failure of scale;
larger models hallucinate more confidently. It is a consequence of the
architecture, and any future form that does not address it will face the same
ceiling.
Linguistic
competence is not world understanding
A model trained on text has learned the
statistical structure of human description of the world — not the structure of
the world itself. The gap between these two things is measurable and
consequential. Tasks that require genuine causal reasoning, physical intuition,
or robust generalisation to novel physical situations reveal it sharply.
These four constraints are the load-bearing
walls of the current situation. They define the space within which the next
synthesis must operate. A successor form that ignores any of them will not
succeed; one that resolves all four will define the field for the decade that
follows.
IV
The
current collision: four pressures on the foundation model
We are now inside the
second collision. The Foundation Model is the dominant form, and it is under
simultaneous pressure from four directions. The question is not whether it will
be superseded — every dominant form is eventually superseded by the anomalies
it cannot resolve — but how the collision will resolve, and on what timeline.
Competing thesis A — high weight
Agentic systems
A model that generates
text is categorically different from a system that takes actions, uses tools,
plans sequences of steps, and learns from the results of its own interventions.
The passive-generative paradigm is structurally insufficient for the tasks the
field is being asked to perform.
Competing thesis B — high weight
Deliberative reasoning
Single-pass next-token
prediction — however capable — is structurally different from slow, iterative,
self-correcting reasoning. The gap shows up sharply in mathematics, formal
logic, and multi-step planning. A different mode of processing, not just more
scale, appears necessary.
Competing thesis C — medium weight
Physical grounding
Language models
trained on text descriptions of the world cannot develop robust causal models
of the world. Only systems that interact with physical environments — directly or
through embodied simulation — can close this gap. The thesis is empirically
strong but institutionally expensive.
Competing thesis D — rising weight
Formal verification
In high-stakes domains — medicine, law,
engineering, mathematics — plausibility is not enough. The demand for
verifiable, not merely probable, outputs is growing. Neural systems alone
cannot provide formal guarantees. Hybrid architectures that combine neural
generation with symbolic verification are gaining pressure.
These four theses are
not equally mature. Theses A and B are already in deployment — multi-step
reasoning systems and tool-using agents exist and are producing results that
pure text-generation systems cannot match. Thesis C is empirically
well-supported but requires physical infrastructure that slows its absorption.
Thesis D is gaining strength from anomalies in theses A and B: agents and
reasoners fail in high-stakes formal domains in ways that create visible,
consequential failures.
The question of which combination of these
theses produces the next synthesis — and when — is the central predictive
question for the field over the next five years.
V
Four
foresights: 2026–2031
What follows are not
predictions in the forecaster's sense — probabilities assigned to discrete outcomes.
They are structural foresights: projections of where the current collision is
being driven by its own internal logic. They could be wrong in timing; they are
unlikely to be wrong in direction.
Foresight 1
The dominant AI
interface becomes agentic before it becomes conversational everywhere
The conversational
model — user asks, system responds, user reads — is a transitional form, not a
final one. It emerged because it was the most legible interface for
probabilistic text generation. But the problems the field is being mobilised to
solve — complex research, software development, organisational knowledge work,
scientific investigation — are not conversational in structure. They are
sequential, iterative, tool-dependent, and require maintaining context across
dozens of steps and multiple information sources simultaneously.
The pressure from
thesis A (agentic systems) is already producing deployment evidence. The
question is not whether agentic systems will become dominant but how quickly
the infrastructure — tool ecosystems, verification mechanisms, human oversight
protocols — catches up with the underlying capability. The form that resolves
this will not look like a better chatbot. It will look like a capable junior
colleague who can be given a goal and trusted to pursue it responsibly across a
working day.
The institutions that
adapt their workflows to this form early will accumulate significant structural
advantages. Those that treat agentic AI as merely a faster version of
conversational AI will find themselves operating with a systematically inferior
tool.
Signal to watch: The ratio of agentic
to single-turn API calls in enterprise deployments. When it crosses parity, the
transition has occurred in practice regardless of public narrative.
Foresight 2
Deliberative reasoning
displaces retrieval as the primary mechanism for reliability
The current dominant
response to the hallucination problem is retrieval-augmented generation: give
the model access to external documents and instruct it to ground its answers in
retrieved text. This is a reasonable interim solution and it does reduce
hallucination rates in constrained domains. But it is a compensation strategy,
not a structural solution. A model that retrieves accurately but reasons poorly
will confidently produce wrong conclusions from correct premises — which may be
more dangerous than a model that retrieves inaccurately.
The deeper pressure
comes from thesis B: slow, deliberative, self-correcting reasoning as a
genuinely different mode from single-pass generation. Systems that can
formulate hypotheses, check them, identify contradictions, backtrack, and
revise — that can, in effect, show their work in a way that exposes errors
before they reach the output — address the reliability problem at a deeper level
than retrieval does. The empirical results from extended-thinking systems in
mathematics and formal reasoning domains already indicate that this mode
produces a qualitatively different class of output.
The synthesis that
absorbs both agentic capability and deliberative reasoning will produce a
system that is not merely more capable but differently trustworthy — one whose
reasoning process can be inspected, and whose errors can therefore be
identified and corrected rather than merely detected after the fact.
Signal to watch: Benchmark
performance gaps between single-pass and extended-thinking modes on novel
formal problems — especially problems not representable in training data. A
widening gap confirms the structural claim.
Foresight 3
The alignment tension
inverts: interpretability becomes a capability amplifier
The current framing of
the alignment problem treats safety and capability as being in tension — a view
that is empirically defensible in the short run and strategically damaging in
the medium run. The framing produces an arms race logic in which safety-focused
labs are presumed to be trading capability for alignment, and
capability-focused labs are presumed to be doing the reverse.
This framing will not
survive the next five years. The reason is mechanistic interpretability — the
programme of research that seeks to understand, at a functional level, what is
happening inside neural networks when they produce outputs. As this programme
matures, its findings will not merely make systems safer. They will make
systems more capable, because understanding the mechanism of reasoning allows
its improvement in ways that blind scaling cannot.
A system whose
internal reasoning can be inspected is a system whose reasoning can be
improved, debugged, and composed with other systems in principled ways. The
current opacity of large neural networks is not a feature — it is a limitation
that happens to create safety concerns as a side effect. Resolving the opacity
resolves both the safety concern and the capability ceiling simultaneously. The
labs that understand this early will find that interpretability work is not a
cost imposed by alignment considerations but an investment that pays dual
returns.
Signal to watch: Publication of
capability improvements — not just safety results — attributable to
interpretability research. The moment interpretability labs begin publishing
performance benchmarks alongside safety benchmarks, the framing has shifted.
Foresight 4
The next polarity is
verifiability: neuro-symbolic integration emerges as the defining tension of
the early 2030s
This foresight
concerns not the immediate period but the conflict that the current synthesis
will produce as it matures. Thesis D — formal verification through
neuro-symbolic hybrid architectures — is currently the least mature of the four
competing pressures. It is gaining strength not from its own successes but from
the failures of the other three.
Agentic systems
operating in high-stakes domains — medical diagnosis, legal analysis,
engineering design, financial modelling — will encounter a class of failure
that neither scale nor deliberative reasoning can resolve. These are domains
where the cost of plausible-but-wrong outputs is not inconvenience but harm.
They require not merely high-probability correct answers but verifiably correct
answers — outputs that can be checked against formal criteria and found to be
valid or invalid in a binary sense.
Neural systems cannot
provide this. Symbolic systems can provide it but cannot match neural systems
on the ill-structured, ambiguous, natural-language-embedded aspects of real
high-stakes problems. The pressure for a synthesis that combines both will
intensify as agentic AI enters regulated domains and accumulates visible,
consequential failures.
The institutions best
positioned for this transition are those that develop hybrid literacy now —
that build teams capable of working across the neural and symbolic traditions
before the pressure to do so becomes acute. The pressure will become acute; the
question is whether organisations are prepared for it or caught by it.
Signal to watch: Regulatory
requirements in medicine, law, and infrastructure that specify verifiability
criteria for AI outputs. When regulators begin writing formal requirements
rather than principles, the pressure has become institutional and the timeline
to synthesis has shortened.
VI
What
this analysis does not resolve
Honest foresight names
its own limits with the same precision it brings to its claims.
The
timing problem
This analysis identifies
the direction of the next synthesis with reasonable confidence. It does not
identify the timeline. The gap between structural necessity and actual arrival
can be months or a decade, depending on factors — institutional investment,
regulatory environment, hardware availability, key personnel movements — that
are not derivable from the intellectual logic of the field. Those who confuse
directional confidence with timing confidence will make expensive mistakes.
The
displacement question
This analysis does not
predict which actors will produce the next synthesis. The history of technology
is replete with cases where the actors who identified the direction of a
transition were not the ones who executed it. Understanding what is coming is
not the same as being positioned to deliver it. Foresight is a necessary
condition for strategic preparation; it is not a sufficient one.
The
black swan caveat
The four competing
theses identified here are the ones visible from within the current
intellectual field. A fifth pressure — from a domain not currently in
conversation with generative AI, or from a theoretical breakthrough with no
precedent in recent history — could reorganise the field in ways this analysis
could not anticipate. Structural foresight is not comprehensive foresight. It
is the best available reading of the visible pressures; it is not a claim that
all relevant pressures are visible.
The
political economy of knowledge
The synthesis that the intellectual logic of
the field demands is not automatically the synthesis that dominant institutions
will produce or recognise. Investment cycles, competitive incentives, and the
organisational conservatism of large incumbents can delay, distort, or
misattribute the synthesis when it arrives. The analysis here is of
intellectual structure; a full strategic analysis would also require an
analysis of institutional structure, and those two analyses do not always point
in the same direction.
The field of
generative AI is not in a period of open-ended possibility. It is in a period
of constrained conflict — four inadequacies pressing against a stable but
structurally insufficient dominant form, four competing theses pressing toward
a synthesis that the current constraints have already substantially shaped. The
analyst who reads this situation clearly does not merely understand where the
field has been. They see what it cannot avoid becoming.
Srijan
Sanchar · srijansanchar.com Foresight Document · 20